class: center, middle, inverse, title-slide # Foundations of inference --- class: inverse, center, middle # Recall --- ## The statistical process Statistics is a process that converts data into useful information, whereby practitioners 1. form a question of interest, 2. collect and summarize data, 3. and interpret the results. --- ## The population of interest The .vocab[population] is the group we'd like to learn something about. For example: - What is the prevalence of diabetes among **U.S. adults**, and has it changed over time? - Does the average amount of caffeine vary by vendor in **12 oz. cups of** **coffee at Duke coffee shops**? - Is there a relationship between tumor type and five-year mortality among **breast cancer patients**? The .vocab[research question of interest] is what we want to answer - often relating one or more numerical quantities or summary statistics. If we had data from every unit in the population, we could just calculate what we wanted and be done! --- ## Sampling from the population Unfortunately, we (usually) have to settle with a .vocab[sample] from the population. Ideally, the sample is .vocab[representative], allowing us to make conclusions that are .vocab[generalizable] to the broader population of interest. In order to make a formal statistical statement about the broader population of interest when all we have is a sample, we need to use the tools of probability and statistical inference. --- ## Big picture <img src="12-found-inf_files/figure-html/unnamed-chunk-2-1.png" style="display: block; margin: auto;" /> Let's discuss a few population characteristics we might be interested in. --- class: inverse, center, middle # Terminology --- ## Explanatory and response variables When we suspect one variable might causally affect another, we label the first variable the .vocab[explanatory variable] and the second the .vocab[response variable]. *Whether or not we can actually make this causal connection will depend on the type of statistical study (more on this shortly).* <br/> `$$\mbox{Explanatory Variable} \longrightarrow \mbox{Response Variable}$$` -- <br/> Do larger homes in good locations lead to higher home selling prices? What are the explanatory and response variables? --- ## Population, parameter; sample, statistic .vocab[Population]: a group of individuals or objects we are interested in studying .vocab[Parameter]: a numerical quantity derived from the population (almost always unknown) - Parameters could be the mean, median, correlation, maximum, etc. If we had data from every unit in the population, we could just calculate population parameters and be done! **Unfortunately, we usually cannot do this.** --- ## Take a sample .vocab[Sample]: a subset of our population of interest .vocab[Statistic]: a numerical quantity derived from a sample - Statistics could be the mean, median, correlation, maximum, etc. Naturally, it makes sense to use the sample mean (and other quantities derived from the sample) to make generalizations about the population mean. --- ## Statistical inference .vocab[Statistical inference] is the process of using sample data to make conclusions about the underlying population the sample came from. - .vocab[Estimation]: estimating an unknown parameter based on values from the sample at hand - .vocab[Testing]: evaluating whether our observed sample provides evidence for or against some claim about the population In the coming lectures we'll discuss each of these inference approaches. -- <br/> Before we get into this, let's discuss ways samples can be obtained and what type of conclusions we'll be be able to make and **not** make as a result of our statistical process. --- class: inverse, center, middle # Sampling --- ## Sampling strategies - In our discussions on probability, we considered randomly selecting individuals from studies, where each individual was equally likely to be selected. This form of random sampling is known as .vocab[simple random sampling]. -- - .vocab[Stratified sampling] divides the population into .vocab[strata] such that each strata is homogenous. Then a simple random sample is applied within each stratum. -- - .vocab[Cluster sampling] first partitions the population into .vocab[clusters], where each cluster is representative of the population. A fixed number of clusters is selected and all observations within the cluster are included in the sample. -- - .vocab[Multistage sampling] is similar to cluster sampling, but rather than keep all observations in each cluster, only a random sample of observations is kept. --- ## Example Suppose we are interested in estimating the malaria rate in a densely tropical portion of rural Indonesia. We learn that there are 30 villages in that part of the Indonesian jungle, each more or less similar to the next. Our goal is to test 150 individuals for malaria. What are the costs and benefits to using the four aforementioned sampling techniques? ??? - Simple random sample: expensive, may not get good representation from all 30 villages - Stratified sample: not clear how to build strata on an individual basis. If strata are the villages, then some villages will be left out. - Cluster sample / multistage: these are the best options here. --- ## Sample bias - The four sampling strategies help reduce .vocab[bias] in our sample. A biased sample can lead to erroneous conclusions. - Bias can still appear if the non-response rate is very high. - Is our sample representative of the population or is it representative of the population that "responded" to the survey? <img src="12-found-inf_files/figure-html/unnamed-chunk-3-1.png" style="display: block; margin: auto;" /> --- class: inverse, center, middle # Statistical studies and conclusions --- ## Observational studies and experiments - Observational - Collect data in a way that does not interfere with how the data arise ("observe") - Only establish an **association** - Data often cheaper and easier to collect -- - Experimental - Randomly assign subjects to treatments - Establish **causal connections** - Often more expensive - Sometimes it is impossible or unethical to design an experiment --- ## Random sampling vs. random assignment <center> <img src="img/12/random_sample_assign_grid.png" height=400, width=600> </center> What do you think Pfizer did in their trials for the COVID-19 vaccine development? --- class: inverse, center, middle # Pitfalls --- ## "Lucky coincidences" 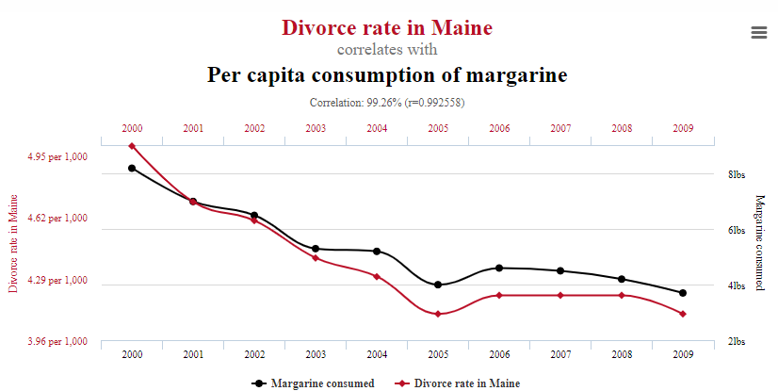 *Source*: [Tyler Vigen's site of spurious correlations:](https://www.tylervigen.com/spurious-correlations) --- ## "Lucky coincidences" 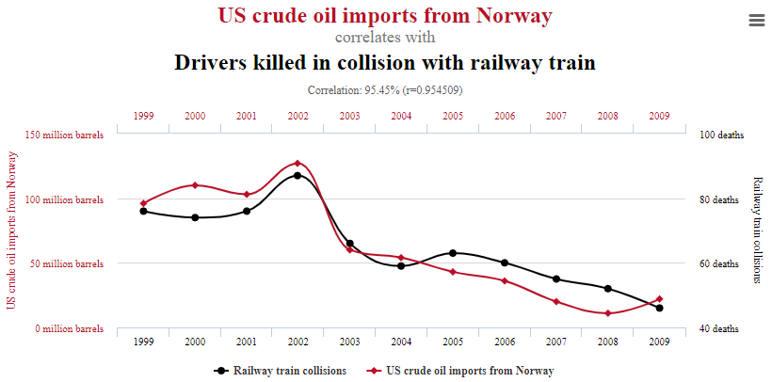 *Source*: [Tyler Vigen's site of spurious correlations:](https://www.tylervigen.com/spurious-correlations) --- ## "Lucky coincidences" 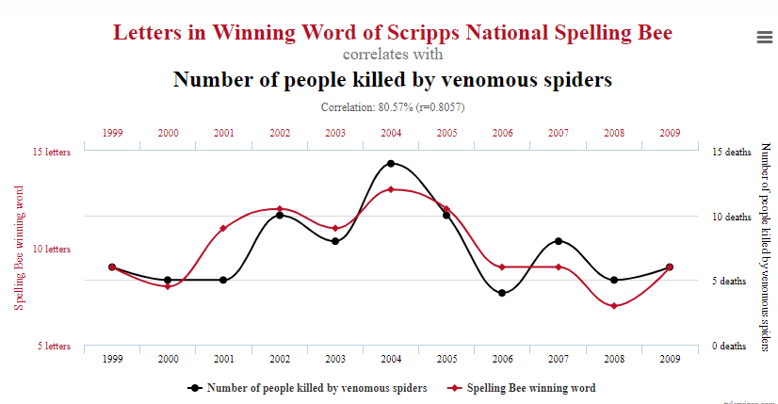 *Source*: [Tyler Vigen's site of spurious correlations:](https://www.tylervigen.com/spurious-correlations) --- ## Confounding variables A .vocab[confounding] variable is an an extraneous variable that affects both the explanatory and the response variable, and makes it seem like there is a relationship between them. -- Identify the confounding variable in each of the following statements: 1. As the amount of ice cream sales increases, the number of shark attacks also increases. 2. The higher the number of firefighters at a fire is, the greater the amount of damage caused by that fire. 3. Taller children are better at both reading and math compared to shorter children. --- Click the link below to create the repository for lecture notes #12. - [https://classroom.github.com/a/Rc4bTdY7](https://classroom.github.com/a/Rc4bTdY7)